Bases de Datos SQL (Relacionales)¶
🌐 Traducción por IA y humanos
Esta traducción fue hecha por IA guiada por humanos. 🤝
Podría tener errores al interpretar el significado original, o sonar poco natural, etc. 🤖
Puedes mejorar esta traducción ayudándonos a guiar mejor al LLM de IA.
FastAPI no requiere que uses una base de datos SQL (relacional). Pero puedes utilizar cualquier base de datos que desees.
Aquí veremos un ejemplo usando SQLModel.
SQLModel está construido sobre SQLAlchemy y Pydantic. Fue creado por el mismo autor de FastAPI para ser la combinación perfecta para aplicaciones de FastAPI que necesiten usar bases de datos SQL.
Consejo
Puedes usar cualquier otro paquete de bases de datos SQL o NoSQL que quieras (en algunos casos llamadas "ORMs"), FastAPI no te obliga a usar nada. 😎
Como SQLModel se basa en SQLAlchemy, puedes usar fácilmente cualquier base de datos soportada por SQLAlchemy (lo que las hace también soportadas por SQLModel), como:
- PostgreSQL
- MySQL
- SQLite
- Oracle
- Microsoft SQL Server, etc.
En este ejemplo, usaremos SQLite, porque utiliza un solo archivo y Python tiene soporte integrado. Así que puedes copiar este ejemplo y ejecutarlo tal cual.
Más adelante, para tu aplicación en producción, es posible que desees usar un servidor de base de datos como PostgreSQL.
Consejo
Hay un generador de proyectos oficial con FastAPI y PostgreSQL que incluye un frontend y más herramientas: https://github.com/fastapi/full-stack-fastapi-template
Este es un tutorial muy simple y corto, si deseas aprender sobre bases de datos en general, sobre SQL o más funcionalidades avanzadas, ve a la documentación de SQLModel.
Instalar SQLModel¶
Primero, asegúrate de crear tu entorno virtual, actívalo, y luego instala sqlmodel:
$ pip install sqlmodel
---> 100%
Crear la App con un Solo Modelo¶
Primero crearemos la versión más simple de la aplicación con un solo modelo de SQLModel.
Más adelante la mejoraremos aumentando la seguridad y versatilidad con múltiples modelos a continuación. 🤓
Crear Modelos¶
Importa SQLModel y crea un modelo de base de datos:
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: SessionDep) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: SessionDep) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: Session = Depends(get_session)) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: Session = Depends(get_session)) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
La clase Hero es muy similar a un modelo de Pydantic (de hecho, en el fondo, realmente es un modelo de Pydantic).
Hay algunas diferencias:
-
table=Truele dice a SQLModel que este es un modelo de tabla, que debe representar una tabla en la base de datos SQL, no es solo un modelo de datos (como lo sería cualquier otra clase regular de Pydantic). -
Field(primary_key=True)le dice a SQLModel queides la clave primaria en la base de datos SQL (puedes aprender más sobre claves primarias de SQL en la documentación de SQLModel).Nota: Usamos
int | Nonepara el campo de clave primaria para que en el código Python podamos crear un objeto sin unid(id=None), asumiendo que la base de datos lo generará al guardar. SQLModel entiende que la base de datos proporcionará elidy define la columna como unINTEGERno nulo en el esquema de la base de datos. Consulta la documentación de SQLModel sobre claves primarias para más detalles. -
Field(index=True)le dice a SQLModel que debe crear un índice SQL para esta columna, lo que permitirá búsquedas más rápidas en la base de datos cuando se lean datos filtrados por esta columna.SQLModel sabrá que algo declarado como
strserá una columna SQL de tipoTEXT(oVARCHAR, dependiendo de la base de datos).
Crear un Engine¶
Un engine de SQLModel (en el fondo, realmente es un engine de SQLAlchemy) es lo que mantiene las conexiones a la base de datos.
Tendrías un solo objeto engine para todo tu código para conectar a la misma base de datos.
# Code above omitted 👆
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: SessionDep) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: SessionDep) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: Session = Depends(get_session)) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: Session = Depends(get_session)) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Usar check_same_thread=False permite a FastAPI usar la misma base de datos SQLite en diferentes hilos. Esto es necesario ya que una sola request podría usar más de un hilo (por ejemplo, en dependencias).
No te preocupes, con la forma en que está estructurado el código, nos aseguraremos de usar una sola session de SQLModel por request más adelante, esto es realmente lo que intenta lograr el check_same_thread.
Crear las Tablas¶
Luego añadimos una función que usa SQLModel.metadata.create_all(engine) para crear las tablas para todos los modelos de tabla.
# Code above omitted 👆
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: SessionDep) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: SessionDep) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: Session = Depends(get_session)) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: Session = Depends(get_session)) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Crear una Dependencia de Session¶
Una Session es lo que almacena los objetos en memoria y lleva un seguimiento de cualquier cambio necesario en los datos, luego usa el engine para comunicarse con la base de datos.
Crearemos una dependencia de FastAPI con yield que proporcionará una nueva Session para cada request. Esto es lo que asegura que usemos una sola session por request. 🤓
Luego creamos una dependencia Annotated SessionDep para simplificar el resto del código que usará esta dependencia.
# Code above omitted 👆
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: SessionDep) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: SessionDep) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: Session = Depends(get_session)) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: Session = Depends(get_session)) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Crear Tablas de Base de Datos al Arrancar¶
Crearemos las tablas de la base de datos cuando arranque la aplicación.
# Code above omitted 👆
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: SessionDep) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: SessionDep) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: Session = Depends(get_session)) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: Session = Depends(get_session)) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Aquí creamos las tablas en un evento de inicio de la aplicación.
Para producción probablemente usarías un script de migración que se ejecuta antes de iniciar tu aplicación. 🤓
Consejo
SQLModel tendrá utilidades de migración envolviendo Alembic, pero por ahora, puedes usar Alembic directamente.
Crear un Hero¶
Debido a que cada modelo de SQLModel también es un modelo de Pydantic, puedes usarlo en las mismas anotaciones de tipos que podrías usar en modelos de Pydantic.
Por ejemplo, si declaras un parámetro de tipo Hero, será leído desde el JSON body.
De la misma manera, puedes declararlo como el tipo de retorno de la función, y luego la forma de los datos aparecerá en la interfaz automática de documentación de la API.
# Code above omitted 👆
@app.post("/heroes/")
def create_hero(hero: Hero, session: SessionDep) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: SessionDep) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: SessionDep) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: Session = Depends(get_session)) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: Session = Depends(get_session)) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Aquí usamos la dependencia SessionDep (una Session) para añadir el nuevo Hero a la instance Session, comiteamos los cambios a la base de datos, refrescamos los datos en el hero y luego lo devolvemos.
Leer Heroes¶
Podemos leer Heros de la base de datos usando un select(). Podemos incluir un limit y offset para paginar los resultados.
# Code above omitted 👆
@app.get("/heroes/")
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: SessionDep) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: SessionDep) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: Session = Depends(get_session)) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: Session = Depends(get_session)) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Leer Un Hero¶
Podemos leer un único Hero.
# Code above omitted 👆
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: SessionDep) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: SessionDep) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: SessionDep) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: Session = Depends(get_session)) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: Session = Depends(get_session)) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Eliminar un Hero¶
También podemos eliminar un Hero.
# Code above omitted 👆
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: SessionDep) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: SessionDep) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
secret_name: str
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/")
def create_hero(hero: Hero, session: Session = Depends(get_session)) -> Hero:
session.add(hero)
session.commit()
session.refresh(hero)
return hero
@app.get("/heroes/")
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
) -> list[Hero]:
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}")
def read_hero(hero_id: int, session: Session = Depends(get_session)) -> Hero:
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
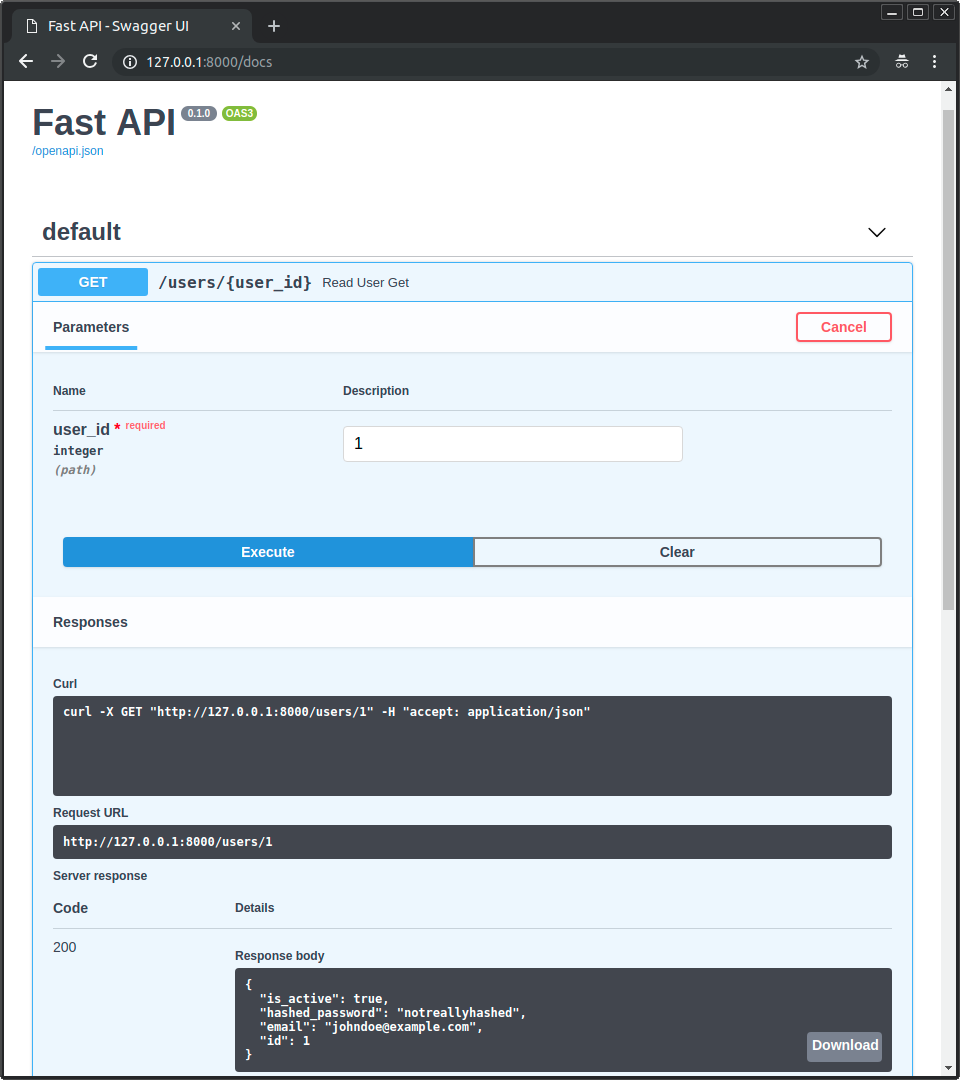
Ejecutar la App¶
Puedes ejecutar la aplicación:
$ fastapi dev
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
Luego dirígete a la interfaz de /docs, verás que FastAPI está usando estos modelos para documentar la API, y los usará para serializar y validar los datos también.
Actualizar la App con Múltiples Modelos¶
Ahora vamos a refactorizar un poco esta aplicación para aumentar la seguridad y la versatilidad.
Si revisas la aplicación anterior, en la interfaz verás que, hasta ahora, permite al cliente decidir el id del Hero a crear. 😱
No deberíamos permitir que eso suceda, podrían sobrescribir un id que ya tenemos asignado en la base de datos. Decidir el id debería ser tarea del backend o la base de datos, no del cliente.
Además, creamos un secret_name para el héroe, pero hasta ahora, lo estamos devolviendo en todas partes, eso no es muy secreto... 😅
Arreglaremos estas cosas añadiendo unos modelos extra. Aquí es donde SQLModel brillará. ✨
Crear Múltiples Modelos¶
En SQLModel, cualquier clase de modelo que tenga table=True es un modelo de tabla.
Y cualquier clase de modelo que no tenga table=True es un modelo de datos, estos son en realidad solo modelos de Pydantic (con un par de pequeñas funcionalidades extra). 🤓
Con SQLModel, podemos usar herencia para evitar duplicar todos los campos en todos los casos.
HeroBase - la clase base¶
Comencemos con un modelo HeroBase que tiene todos los campos que son compartidos por todos los modelos:
nameage
# Code above omitted 👆
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: SessionDep):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(hero_id: int, hero: HeroUpdate, session: SessionDep):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: Session = Depends(get_session)):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(
hero_id: int, hero: HeroUpdate, session: Session = Depends(get_session)
):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Hero - el modelo de tabla¶
Luego, crearemos Hero, el modelo de tabla real, con los campos extra que no siempre están en los otros modelos:
idsecret_name
Debido a que Hero hereda de HeroBase, también tiene los campos declarados en HeroBase, por lo que todos los campos para Hero son:
idnameagesecret_name
# Code above omitted 👆
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: SessionDep):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(hero_id: int, hero: HeroUpdate, session: SessionDep):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: Session = Depends(get_session)):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(
hero_id: int, hero: HeroUpdate, session: Session = Depends(get_session)
):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
HeroPublic - el modelo de datos público¶
A continuación, creamos un modelo HeroPublic, este es el que será devuelto a los clientes de la API.
Tiene los mismos campos que HeroBase, por lo que no incluirá secret_name.
Por fin, la identidad de nuestros héroes está protegida! 🥷
También vuelve a declarar id: int. Al hacer esto, estamos haciendo un contrato con los clientes de la API, para que siempre puedan esperar que el id esté allí y sea un int (nunca será None).
Consejo
Tener el modelo de retorno asegurando que un valor siempre esté disponible y siempre sea int (no None) es muy útil para los clientes de la API, pueden escribir código mucho más simple teniendo esta certeza.
Además, los clientes generados automáticamente tendrán interfaces más simples, para que los desarrolladores que se comuniquen con tu API puedan tener una experiencia mucho mejor trabajando con tu API. 😎
Todos los campos en HeroPublic son los mismos que en HeroBase, con id declarado como int (no None):
idnameage
# Code above omitted 👆
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: SessionDep):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(hero_id: int, hero: HeroUpdate, session: SessionDep):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: Session = Depends(get_session)):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(
hero_id: int, hero: HeroUpdate, session: Session = Depends(get_session)
):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
HeroCreate - el modelo de datos para crear un héroe¶
Ahora creamos un modelo HeroCreate, este es el que validará los datos de los clientes.
Tiene los mismos campos que HeroBase, y también tiene secret_name.
Ahora, cuando los clientes crean un nuevo héroe, enviarán el secret_name, se almacenará en la base de datos, pero esos nombres secretos no se devolverán en la API a los clientes.
Consejo
Esta es la forma en la que manejarías contraseñas. Recíbelas, pero no las devuelvas en la API.
También hashea los valores de las contraseñas antes de almacenarlos, nunca los almacenes en texto plano.
Los campos de HeroCreate son:
nameagesecret_name
# Code above omitted 👆
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: SessionDep):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(hero_id: int, hero: HeroUpdate, session: SessionDep):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: Session = Depends(get_session)):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(
hero_id: int, hero: HeroUpdate, session: Session = Depends(get_session)
):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
HeroUpdate - el modelo de datos para actualizar un héroe¶
No teníamos una forma de actualizar un héroe en la versión anterior de la aplicación, pero ahora con múltiples modelos, podemos hacerlo. 🎉
El modelo de datos HeroUpdate es algo especial, tiene todos los mismos campos que serían necesarios para crear un nuevo héroe, pero todos los campos son opcionales (todos tienen un valor por defecto). De esta forma, cuando actualices un héroe, puedes enviar solo los campos que deseas actualizar.
Debido a que todos los campos realmente cambian (el tipo ahora incluye None y ahora tienen un valor por defecto de None), necesitamos volver a declararlos.
Realmente no necesitamos heredar de HeroBase porque estamos volviendo a declarar todos los campos. Lo dejaré heredando solo por consistencia, pero esto no es necesario. Es más una cuestión de gusto personal. 🤷
Los campos de HeroUpdate son:
nameagesecret_name
# Code above omitted 👆
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: SessionDep):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(hero_id: int, hero: HeroUpdate, session: SessionDep):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: Session = Depends(get_session)):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(
hero_id: int, hero: HeroUpdate, session: Session = Depends(get_session)
):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Crear con HeroCreate y devolver un HeroPublic¶
Ahora que tenemos múltiples modelos, podemos actualizar las partes de la aplicación que los usan.
Recibimos en la request un modelo de datos HeroCreate, y a partir de él, creamos un modelo de tabla Hero.
Este nuevo modelo de tabla Hero tendrá los campos enviados por el cliente, y también tendrá un id generado por la base de datos.
Luego devolvemos el mismo modelo de tabla Hero tal cual desde la función. Pero como declaramos el response_model con el modelo de datos HeroPublic, FastAPI usará HeroPublic para validar y serializar los datos.
# Code above omitted 👆
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: SessionDep):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: SessionDep):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(hero_id: int, hero: HeroUpdate, session: SessionDep):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: Session = Depends(get_session)):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(
hero_id: int, hero: HeroUpdate, session: Session = Depends(get_session)
):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Consejo
Ahora usamos response_model=HeroPublic en lugar de la anotación de tipo de retorno -> HeroPublic porque el valor que estamos devolviendo en realidad no es un HeroPublic.
Si hubiéramos declarado -> HeroPublic, tu editor y linter se quejarían (con razón) de que estás devolviendo un Hero en lugar de un HeroPublic.
Al declararlo en response_model le estamos diciendo a FastAPI que haga lo suyo, sin interferir con las anotaciones de tipos y la ayuda de tu editor y otras herramientas.
Leer Heroes con HeroPublic¶
Podemos hacer lo mismo que antes para leer Heros, nuevamente, usamos response_model=list[HeroPublic] para asegurar que los datos se validen y serialicen correctamente.
# Code above omitted 👆
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: SessionDep):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(hero_id: int, hero: HeroUpdate, session: SessionDep):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: Session = Depends(get_session)):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(
hero_id: int, hero: HeroUpdate, session: Session = Depends(get_session)
):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Leer Un Hero con HeroPublic¶
Podemos leer un único héroe:
# Code above omitted 👆
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: SessionDep):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(hero_id: int, hero: HeroUpdate, session: SessionDep):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: Session = Depends(get_session)):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(
hero_id: int, hero: HeroUpdate, session: Session = Depends(get_session)
):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Actualizar un Hero con HeroUpdate¶
Podemos actualizar un héroe. Para esto usamos una operación HTTP PATCH.
Y en el código, obtenemos un dict con todos los datos enviados por el cliente, solo los datos enviados por el cliente, excluyendo cualquier valor que estaría allí solo por ser valores por defecto. Para hacerlo usamos exclude_unset=True. Este es el truco principal. 🪄
Luego usamos hero_db.sqlmodel_update(hero_data) para actualizar el hero_db con los datos de hero_data.
# Code above omitted 👆
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(hero_id: int, hero: HeroUpdate, session: SessionDep):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
# Code below omitted 👇
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: SessionDep):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(hero_id: int, hero: HeroUpdate, session: SessionDep):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: Session = Depends(get_session)):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(
hero_id: int, hero: HeroUpdate, session: Session = Depends(get_session)
):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Eliminar un Hero de Nuevo¶
Eliminar un héroe se mantiene prácticamente igual.
No satisfaremos el deseo de refactorizar todo en este punto. 😅
# Code above omitted 👆
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
👀 Full file preview
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
SessionDep = Annotated[Session, Depends(get_session)]
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: SessionDep):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: SessionDep,
offset: int = 0,
limit: Annotated[int, Query(le=100)] = 100,
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(hero_id: int, hero: HeroUpdate, session: SessionDep):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: SessionDep):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
🤓 Other versions and variants
Tip
Prefer to use the Annotated version if possible.
from fastapi import Depends, FastAPI, HTTPException, Query
from sqlmodel import Field, Session, SQLModel, create_engine, select
class HeroBase(SQLModel):
name: str = Field(index=True)
age: int | None = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: int | None = Field(default=None, primary_key=True)
secret_name: str
class HeroPublic(HeroBase):
id: int
class HeroCreate(HeroBase):
secret_name: str
class HeroUpdate(HeroBase):
name: str | None = None
age: int | None = None
secret_name: str | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
connect_args = {"check_same_thread": False}
engine = create_engine(sqlite_url, connect_args=connect_args)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
def get_session():
with Session(engine) as session:
yield session
app = FastAPI()
@app.on_event("startup")
def on_startup():
create_db_and_tables()
@app.post("/heroes/", response_model=HeroPublic)
def create_hero(hero: HeroCreate, session: Session = Depends(get_session)):
db_hero = Hero.model_validate(hero)
session.add(db_hero)
session.commit()
session.refresh(db_hero)
return db_hero
@app.get("/heroes/", response_model=list[HeroPublic])
def read_heroes(
session: Session = Depends(get_session),
offset: int = 0,
limit: int = Query(default=100, le=100),
):
heroes = session.exec(select(Hero).offset(offset).limit(limit)).all()
return heroes
@app.get("/heroes/{hero_id}", response_model=HeroPublic)
def read_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
return hero
@app.patch("/heroes/{hero_id}", response_model=HeroPublic)
def update_hero(
hero_id: int, hero: HeroUpdate, session: Session = Depends(get_session)
):
hero_db = session.get(Hero, hero_id)
if not hero_db:
raise HTTPException(status_code=404, detail="Hero not found")
hero_data = hero.model_dump(exclude_unset=True)
hero_db.sqlmodel_update(hero_data)
session.add(hero_db)
session.commit()
session.refresh(hero_db)
return hero_db
@app.delete("/heroes/{hero_id}")
def delete_hero(hero_id: int, session: Session = Depends(get_session)):
hero = session.get(Hero, hero_id)
if not hero:
raise HTTPException(status_code=404, detail="Hero not found")
session.delete(hero)
session.commit()
return {"ok": True}
Ejecutar la App de Nuevo¶
Puedes ejecutar la aplicación de nuevo:
$ fastapi dev
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
Si vas a la interfaz de /docs de la API, verás que ahora está actualizada, y no esperará recibir el id del cliente al crear un héroe, etc.
Resumen¶
Puedes usar SQLModel para interactuar con una base de datos SQL y simplificar el código con modelos de datos y modelos de tablas.
Puedes aprender mucho más en la documentación de SQLModel, hay un mini tutorial más largo sobre el uso de SQLModel con FastAPI. 🚀