Deployment-Konzepte¶
🌐 Übersetzung durch KI und Menschen
Diese Übersetzung wurde von KI erstellt, angeleitet von Menschen. 🤝
Sie könnte Fehler enthalten, etwa Missverständnisse des ursprünglichen Sinns oder unnatürliche Formulierungen, usw. 🤖
Sie können diese Übersetzung verbessern, indem Sie uns helfen, die KI-LLM besser anzuleiten.
Beim Deployment einer FastAPI-Anwendung, oder eigentlich jeder Art von Web-API, gibt es mehrere Konzepte, die Sie wahrscheinlich interessieren, und mithilfe derer Sie die am besten geeignete Methode zum Deployment Ihrer Anwendung finden können.
Einige wichtige Konzepte sind:
- Sicherheit – HTTPS
- Beim Hochfahren ausführen
- Neustarts
- Replikation (die Anzahl der laufenden Prozesse)
- Arbeitsspeicher
- Schritte vor dem Start
Wir werden sehen, wie diese sich auf das Deployment auswirken.
Letztendlich besteht das ultimative Ziel darin, Ihre API-Clients auf sichere Weise zu versorgen, um Unterbrechungen zu vermeiden und die Rechenressourcen (z. B. entfernte Server/virtuelle Maschinen) so effizient wie möglich zu nutzen. 🚀
Ich erzähle Ihnen hier etwas mehr über diese Konzepte, was Ihnen hoffentlich die Intuition gibt, die Sie benötigen, um zu entscheiden, wie Sie Ihre API in sehr unterschiedlichen Umgebungen deployen, möglicherweise sogar in zukünftigen, die jetzt noch nicht existieren.
Durch die Berücksichtigung dieser Konzepte können Sie die beste Variante des Deployments Ihrer eigenen APIs evaluieren und konzipieren.
In den nächsten Kapiteln werde ich Ihnen mehr konkrete Rezepte für das Deployment von FastAPI-Anwendungen geben.
Aber schauen wir uns zunächst einmal diese grundlegenden konzeptionellen Ideen an. Diese Konzepte gelten auch für jede andere Art von Web-API. 💡
Sicherheit – HTTPS¶
Im vorherigen Kapitel über HTTPS haben wir erfahren, wie HTTPS Verschlüsselung für Ihre API bereitstellt.
Wir haben auch gesehen, dass HTTPS normalerweise von einer Komponente außerhalb Ihres Anwendungsservers bereitgestellt wird, einem TLS-Terminierungsproxy.
Und es muss etwas geben, das für die Erneuerung der HTTPS-Zertifikate zuständig ist, es könnte sich um dieselbe Komponente handeln oder um etwas anderes.
Beispieltools für HTTPS¶
Einige der Tools, die Sie als TLS-Terminierungsproxy verwenden können, sind:
- Traefik
- Handhabt automatisch Zertifikat-Erneuerungen ✨
- Caddy
- Handhabt automatisch Zertifikat-Erneuerungen ✨
- Nginx
- Mit einer externen Komponente wie Certbot für Zertifikat-Erneuerungen
- HAProxy
- Mit einer externen Komponente wie Certbot für Zertifikat-Erneuerungen
- Kubernetes mit einem Ingress Controller wie Nginx
- Mit einer externen Komponente wie cert-manager für Zertifikat-Erneuerungen
- Es wird intern von einem Cloudanbieter als Teil seiner Dienste verwaltet (siehe unten 👇)
Eine andere Möglichkeit besteht darin, dass Sie einen Cloud-Dienst verwenden, der den größten Teil der Arbeit übernimmt, einschließlich der Einrichtung von HTTPS. Er könnte einige Einschränkungen haben oder Ihnen mehr in Rechnung stellen, usw. In diesem Fall müssten Sie jedoch nicht selbst einen TLS-Terminierungsproxy einrichten.
In den nächsten Kapiteln zeige ich Ihnen einige konkrete Beispiele.
Die nächsten zu berücksichtigenden Konzepte drehen sich dann um das Programm, das Ihre eigentliche API ausführt (z. B. Uvicorn).
Programm und Prozess¶
Wir werden viel über den laufenden „Prozess“ sprechen, daher ist es nützlich, Klarheit darüber zu haben, was das bedeutet und was der Unterschied zum Wort „Programm“ ist.
Was ein Programm ist¶
Das Wort Programm wird häufig zur Beschreibung vieler Dinge verwendet:
- Der Code, den Sie schreiben, die Python-Dateien.
- Die Datei, die vom Betriebssystem ausgeführt werden kann, zum Beispiel:
python,python.exeoderuvicorn. - Ein bestimmtes Programm, während es auf dem Betriebssystem läuft, die CPU nutzt und Dinge im Arbeitsspeicher ablegt. Dies wird auch als Prozess bezeichnet.
Was ein Prozess ist¶
Das Wort Prozess wird normalerweise spezifischer verwendet und bezieht sich nur auf das, was im Betriebssystem ausgeführt wird (wie im letzten Punkt oben):
- Ein bestimmtes Programm, während es auf dem Betriebssystem ausgeführt wird.
- Dies bezieht sich weder auf die Datei noch auf den Code, sondern speziell auf das, was vom Betriebssystem ausgeführt und verwaltet wird.
- Jedes Programm, jeder Code kann nur dann Dinge tun, wenn er ausgeführt wird. Also dann, wenn ein Prozess läuft.
- Der Prozess kann von Ihnen oder vom Betriebssystem terminiert („beendet“, „gekillt“) werden. An diesem Punkt hört er auf zu laufen/ausgeführt zu werden und kann keine Dinge mehr tun.
- Hinter jeder Anwendung, die Sie auf Ihrem Computer ausführen, steckt ein Prozess, jedes laufende Programm, jedes Fenster usw. Und normalerweise laufen viele Prozesse gleichzeitig, während ein Computer eingeschaltet ist.
- Es können mehrere Prozesse desselben Programms gleichzeitig ausgeführt werden.
Wenn Sie sich den „Task-Manager“ oder „Systemmonitor“ (oder ähnliche Tools) in Ihrem Betriebssystem ansehen, können Sie viele dieser laufenden Prozesse sehen.
Und Sie werden beispielsweise wahrscheinlich feststellen, dass mehrere Prozesse dasselbe Browserprogramm ausführen (Firefox, Chrome, Edge, usw.). Normalerweise führen diese einen Prozess pro Browsertab sowie einige andere zusätzliche Prozesse aus.
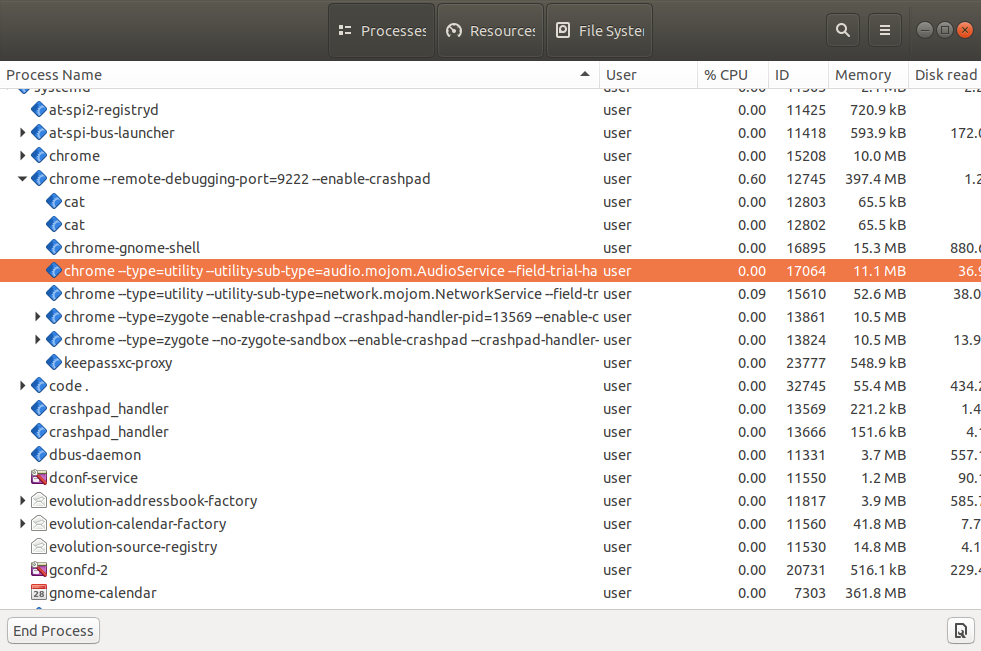
Nachdem wir nun den Unterschied zwischen den Begriffen Prozess und Programm kennen, sprechen wir weiter über das Deployment.
Beim Hochfahren ausführen¶
Wenn Sie eine Web-API erstellen, möchten Sie in den meisten Fällen, dass diese immer läuft, ununterbrochen, damit Ihre Clients immer darauf zugreifen können. Es sei denn natürlich, Sie haben einen bestimmten Grund, warum Sie möchten, dass diese nur in bestimmten Situationen ausgeführt wird. Meistens möchten Sie jedoch, dass sie ständig ausgeführt wird und verfügbar ist.
Auf einem entfernten Server¶
Wenn Sie einen entfernten Server (einen Cloud-Server, eine virtuelle Maschine, usw.) einrichten, können Sie am einfachsten fastapi run (welches Uvicorn verwendet) oder etwas Ähnliches manuell ausführen, genau wie bei der lokalen Entwicklung.
Und es wird funktionieren und während der Entwicklung nützlich sein.
Wenn Ihre Verbindung zum Server jedoch unterbrochen wird, wird der laufende Prozess wahrscheinlich abstürzen.
Und wenn der Server neu gestartet wird (z. B. nach Updates oder Migrationen vom Cloudanbieter), werden Sie das wahrscheinlich nicht bemerken. Und deshalb wissen Sie nicht einmal, dass Sie den Prozess manuell neu starten müssen. Ihre API bleibt also einfach tot. 😱
Beim Hochfahren automatisch ausführen¶
Im Allgemeinen möchten Sie wahrscheinlich, dass das Serverprogramm (z. B. Uvicorn) beim Hochfahren des Servers automatisch gestartet wird und kein menschliches Eingreifen erforderlich ist, sodass immer ein Prozess mit Ihrer API ausgeführt wird (z. B. Uvicorn, welches Ihre FastAPI-Anwendung ausführt).
Separates Programm¶
Um dies zu erreichen, haben Sie normalerweise ein separates Programm, welches sicherstellt, dass Ihre Anwendung beim Hochfahren ausgeführt wird. Und in vielen Fällen würde es auch sicherstellen, dass auch andere Komponenten oder Anwendungen ausgeführt werden, beispielsweise eine Datenbank.
Beispieltools zur Ausführung beim Hochfahren¶
Einige Beispiele für Tools, die diese Aufgabe übernehmen können, sind:
- Docker
- Kubernetes
- Docker Compose
- Docker im Swarm-Modus
- Systemd
- Supervisor
- Es wird intern von einem Cloudanbieter im Rahmen seiner Dienste verwaltet
- Andere ...
In den nächsten Kapiteln werde ich Ihnen konkretere Beispiele geben.
Neustart¶
Ähnlich wie Sie sicherstellen möchten, dass Ihre Anwendung beim Hochfahren ausgeführt wird, möchten Sie wahrscheinlich auch sicherstellen, dass diese nach Fehlern neu gestartet wird.
Wir machen Fehler¶
Wir, als Menschen, machen ständig Fehler. Software hat fast immer Bugs, die an verschiedenen Stellen versteckt sind. 🐛
Und wir als Entwickler verbessern den Code ständig, wenn wir diese Bugs finden und neue Funktionen implementieren (und möglicherweise auch neue Bugs hinzufügen 😅).
Kleine Fehler automatisch handhaben¶
Wenn beim Erstellen von Web-APIs mit FastAPI ein Fehler in unserem Code auftritt, wird FastAPI ihn normalerweise auf den einzelnen Request beschränken, der den Fehler ausgelöst hat. 🛡
Der Client erhält für diesen Request einen 500 Internal Server Error, aber die Anwendung arbeitet bei den nächsten Requests weiter, anstatt einfach komplett abzustürzen.
Größere Fehler – Abstürze¶
Dennoch kann es vorkommen, dass wir Code schreiben, der die gesamte Anwendung zum Absturz bringt und so zum Absturz von Uvicorn und Python führt. 💥
Und dennoch möchten Sie wahrscheinlich nicht, dass die Anwendung tot bleibt, weil an einer Stelle ein Fehler aufgetreten ist. Sie möchten wahrscheinlich, dass sie zumindest für die Pfadoperationen, die nicht fehlerhaft sind, weiterläuft.
Neustart nach Absturz¶
Aber in den Fällen mit wirklich schwerwiegenden Fehlern, die den laufenden Prozess zum Absturz bringen, benötigen Sie eine externe Komponente, die den Prozess neu startet, zumindest ein paar Mal ...
Tipp
... Obwohl es wahrscheinlich keinen Sinn macht, sie immer wieder neu zu starten, wenn die gesamte Anwendung einfach sofort abstürzt. Aber in diesen Fällen werden Sie es wahrscheinlich während der Entwicklung oder zumindest direkt nach dem Deployment bemerken.
Konzentrieren wir uns also auf die Hauptfälle, in denen die Anwendung in bestimmten Fällen in der Zukunft völlig abstürzen könnte und es dann dennoch sinnvoll ist, sie neu zu starten.
Sie möchten wahrscheinlich, dass eine externe Komponente für den Neustart Ihrer Anwendung verantwortlich ist, da zu diesem Zeitpunkt dieselbe Anwendung mit Uvicorn und Python bereits abgestürzt ist und es daher nichts im selben Code derselben Anwendung gibt, was etwas dagegen tun kann.
Beispieltools zum automatischen Neustart¶
In den meisten Fällen wird dasselbe Tool, das zum Ausführen des Programms beim Hochfahren verwendet wird, auch für automatische Neustarts verwendet.
Dies könnte zum Beispiel erledigt werden durch:
- Docker
- Kubernetes
- Docker Compose
- Docker im Swarm-Modus
- Systemd
- Supervisor
- Intern von einem Cloudanbieter im Rahmen seiner Dienste
- Andere ...
Replikation – Prozesse und Arbeitsspeicher¶
Wenn Sie eine FastAPI-Anwendung verwenden und ein Serverprogramm wie den fastapi-Befehl, der Uvicorn ausführt, kann die Ausführung in einem Prozess mehrere Clients gleichzeitig versorgen.
In vielen Fällen möchten Sie jedoch mehrere Workerprozesse gleichzeitig ausführen.
Mehrere Prozesse – Worker¶
Wenn Sie mehr Clients haben, als ein einzelner Prozess verarbeiten kann (z. B. wenn die virtuelle Maschine nicht sehr groß ist) und die CPU des Servers mehrere Kerne hat, dann könnten mehrere Prozesse gleichzeitig mit derselben Anwendung laufen und alle Requests unter sich verteilen.
Wenn Sie mit mehreren Prozessen dasselbe API-Programm ausführen, werden diese üblicherweise als Worker bezeichnet.
Workerprozesse und Ports¶
Erinnern Sie sich aus der Dokumentation Über HTTPS, dass nur ein Prozess auf einer Kombination aus Port und IP-Adresse auf einem Server lauschen kann?
Das ist immer noch wahr.
Um also mehrere Prozesse gleichzeitig zu haben, muss es einen einzelnen Prozess geben, der einen Port überwacht, welcher dann die Kommunikation auf irgendeine Weise an jeden Workerprozess überträgt.
Arbeitsspeicher pro Prozess¶
Wenn das Programm nun Dinge in den Arbeitsspeicher lädt, zum Beispiel ein Modell für maschinelles Lernen in einer Variablen oder den Inhalt einer großen Datei in einer Variablen, verbraucht das alles einen Teil des Arbeitsspeichers (RAM – Random Access Memory) des Servers.
Und mehrere Prozesse teilen sich normalerweise keinen Speicher. Das bedeutet, dass jeder laufende Prozess seine eigenen Dinge, eigenen Variablen und eigenen Speicher hat. Und wenn Sie in Ihrem Code viel Speicher verbrauchen, verbraucht jeder Prozess die gleiche Menge Speicher.
Serverspeicher¶
Wenn Ihr Code beispielsweise ein Machine-Learning-Modell mit 1 GB Größe lädt und Sie einen Prozess mit Ihrer API ausführen, verbraucht dieser mindestens 1 GB RAM. Und wenn Sie 4 Prozesse (4 Worker) starten, verbraucht jeder 1 GB RAM. Insgesamt verbraucht Ihre API also 4 GB RAM.
Und wenn Ihr entfernter Server oder Ihre virtuelle Maschine nur über 3 GB RAM verfügt, führt der Versuch, mehr als 4 GB RAM zu laden, zu Problemen. 🚨
Mehrere Prozesse – Ein Beispiel¶
Im folgenden Beispiel gibt es einen Manager-Prozess, welcher zwei Workerprozesse startet und steuert.
Dieser Manager-Prozess wäre wahrscheinlich derjenige, welcher der IP am Port lauscht. Und er würde die gesamte Kommunikation an die Workerprozesse weiterleiten.
Diese Workerprozesse würden Ihre Anwendung ausführen, sie würden die Hauptberechnungen durchführen, um einen Request entgegenzunehmen und eine Response zurückzugeben, und sie würden alles, was Sie in Variablen einfügen, in den RAM laden.

Und natürlich würden auf derselben Maschine neben Ihrer Anwendung wahrscheinlich andere Prozesse laufen.
Ein interessantes Detail ist dabei, dass der Prozentsatz der von jedem Prozess verwendeten CPU im Laufe der Zeit stark variieren kann, der Arbeitsspeicher (RAM) jedoch normalerweise mehr oder weniger stabil bleibt.
Wenn Sie eine API haben, die jedes Mal eine vergleichbare Menge an Berechnungen durchführt, und Sie viele Clients haben, dann wird die CPU-Auslastung wahrscheinlich ebenfalls stabil sein (anstatt ständig schnell zu steigen und zu fallen).
Beispiele für Replikation-Tools und -Strategien¶
Es gibt mehrere Ansätze, um dies zu erreichen, und ich werde Ihnen in den nächsten Kapiteln mehr über bestimmte Strategien erzählen, beispielsweise wenn es um Docker und Container geht.
Die wichtigste zu berücksichtigende Einschränkung besteht darin, dass es eine einzelne Komponente geben muss, welche die öffentliche IP auf dem Port verwaltet. Und dann muss diese irgendwie die Kommunikation weiterleiten, an die replizierten Prozesse/Worker.
Hier sind einige mögliche Kombinationen und Strategien:
- Uvicorn mit
--workers- Ein Uvicorn-Prozessmanager würde der IP am Port lauschen, und er würde mehrere Uvicorn-Workerprozesse starten.
- Kubernetes und andere verteilte Containersysteme
- Etwas in der Kubernetes-Ebene würde die IP und den Port abhören. Die Replikation hätte mehrere Container, in jedem wird jeweils ein Uvicorn-Prozess ausgeführt.
- Cloud-Dienste, welche das für Sie erledigen
- Der Cloud-Dienst wird wahrscheinlich die Replikation für Sie übernehmen. Er würde Sie möglicherweise einen auszuführenden Prozess oder ein zu verwendendes Container-Image definieren lassen, in jedem Fall wäre es höchstwahrscheinlich ein einzelner Uvicorn-Prozess, und der Cloud-Dienst wäre auch verantwortlich für die Replikation.
Tipp
Machen Sie sich keine Sorgen, wenn einige dieser Punkte zu Containern, Docker oder Kubernetes noch nicht viel Sinn ergeben.
Ich werde Ihnen in einem zukünftigen Kapitel mehr über Container-Images, Docker, Kubernetes, usw. erzählen: FastAPI in Containern – Docker.
Schritte vor dem Start¶
Es gibt viele Fälle, in denen Sie, bevor Sie Ihre Anwendung starten, einige Schritte ausführen möchten.
Beispielsweise möchten Sie möglicherweise Datenbankmigrationen ausführen.
In den meisten Fällen möchten Sie diese Schritte jedoch nur einmal ausführen.
Sie möchten also einen einzelnen Prozess haben, um diese Vorab-Schritte auszuführen, bevor Sie die Anwendung starten.
Und Sie müssen sicherstellen, dass es sich um einen einzelnen Prozess handelt, der die Vorab-Schritte ausführt, auch wenn Sie anschließend mehrere Prozesse (mehrere Worker) für die Anwendung selbst starten. Wenn diese Schritte von mehreren Prozessen ausgeführt würden, würden diese die Arbeit verdoppeln, indem sie sie parallel ausführen, und wenn es sich bei den Schritten um etwas Delikates wie eine Datenbankmigration handelt, könnte das miteinander Konflikte verursachen.
Natürlich gibt es Fälle, in denen es kein Problem darstellt, die Vorab-Schritte mehrmals auszuführen. In diesem Fall ist die Handhabung viel einfacher.
Tipp
Bedenken Sie außerdem, dass Sie, abhängig von Ihrer Einrichtung, in manchen Fällen gar keine Vorab-Schritte benötigen, bevor Sie die Anwendung starten.
In diesem Fall müssen Sie sich darüber keine Sorgen machen. 🤷
Beispiele für Strategien für Vorab-Schritte¶
Es hängt stark davon ab, wie Sie Ihr System deployen, und hängt wahrscheinlich mit der Art und Weise zusammen, wie Sie Programme starten, Neustarts durchführen, usw.
Hier sind einige mögliche Ideen:
- Ein „Init-Container“ in Kubernetes, der vor Ihrem Anwendungs-Container ausgeführt wird
- Ein Bash-Skript, das die Vorab-Schritte ausführt und dann Ihre Anwendung startet
- Sie benötigen immer noch eine Möglichkeit, dieses Bash-Skript zu starten/neu zu starten, Fehler zu erkennen, usw.
Tipp
Konkretere Beispiele hierfür mit Containern gebe ich Ihnen in einem späteren Kapitel: FastAPI in Containern – Docker.
Ressourcennutzung¶
Ihr(e) Server ist (sind) eine Ressource, welche Sie mit Ihren Programmen, der Rechenzeit auf den CPUs und dem verfügbaren RAM-Speicher verbrauchen oder nutzen können.
Wie viele Systemressourcen möchten Sie verbrauchen/nutzen? Sie mögen „nicht viel“ denken, aber in Wirklichkeit möchten Sie tatsächlich so viel wie möglich ohne Absturz verwenden.
Wenn Sie für drei Server bezahlen, aber nur wenig von deren RAM und CPU nutzen, verschwenden Sie wahrscheinlich Geld 💸 und wahrscheinlich Strom für den Server 🌎, usw.
In diesem Fall könnte es besser sein, nur zwei Server zu haben und einen höheren Prozentsatz von deren Ressourcen zu nutzen (CPU, Arbeitsspeicher, Festplatte, Netzwerkbandbreite, usw.).
Wenn Sie andererseits über zwei Server verfügen und 100 % ihrer CPU und ihres RAM nutzen, wird irgendwann ein Prozess nach mehr Speicher fragen und der Server muss die Festplatte als „Speicher“ verwenden (was tausendmal langsamer sein kann) oder er könnte sogar abstürzen. Oder ein Prozess muss möglicherweise einige Berechnungen durchführen und müsste warten, bis die CPU wieder frei ist.
In diesem Fall wäre es besser, einen zusätzlichen Server zu besorgen und einige Prozesse darauf auszuführen, damit alle über genug RAM und CPU-Zeit verfügen.
Es besteht auch die Möglichkeit, dass es aus irgendeinem Grund zu Spitzen in der Nutzung Ihrer API kommt. Vielleicht ist diese viral gegangen, oder vielleicht haben andere Dienste oder Bots damit begonnen, sie zu nutzen. Und vielleicht möchten Sie in solchen Fällen über zusätzliche Ressourcen verfügen, um auf der sicheren Seite zu sein.
Sie können eine beliebige Zahl festlegen, um beispielsweise eine Ressourcenauslastung zwischen 50 % und 90 % anzustreben. Der Punkt ist, dass dies wahrscheinlich die wichtigen Dinge sind, die Sie messen und verwenden sollten, um Ihre Deployments zu optimieren.
Sie können einfache Tools wie htop verwenden, um die in Ihrem Server verwendete CPU und den RAM oder die von jedem Prozess verwendete Menge anzuzeigen. Oder Sie können komplexere Überwachungstools verwenden, die möglicherweise auf mehrere Server usw. verteilt sind.
Zusammenfassung¶
Sie haben hier einige der wichtigsten Konzepte gelesen, die Sie wahrscheinlich berücksichtigen müssen, wenn Sie entscheiden, wie Sie Ihre Anwendung deployen:
- Sicherheit – HTTPS
- Beim Hochfahren ausführen
- Neustarts
- Replikation (die Anzahl der laufenden Prozesse)
- Arbeitsspeicher
- Schritte vor dem Start
Das Verständnis dieser Ideen und deren Anwendung sollte Ihnen die nötige Intuition vermitteln, um bei der Konfiguration und Optimierung Ihrer Deployments Entscheidungen zu treffen. 🤓
In den nächsten Abschnitten gebe ich Ihnen konkretere Beispiele für mögliche Strategien, die Sie verfolgen können. 🚀